〇、前言(碎碎念)
上篇讲了内存利用率的问题,但其实Java的内存调优很多时候其实是JVM调优,这个内容也是一个老生常谈的问题了,需要一定的篇幅和案例,之后再讲吧~
CPU篇
先看一段代码:
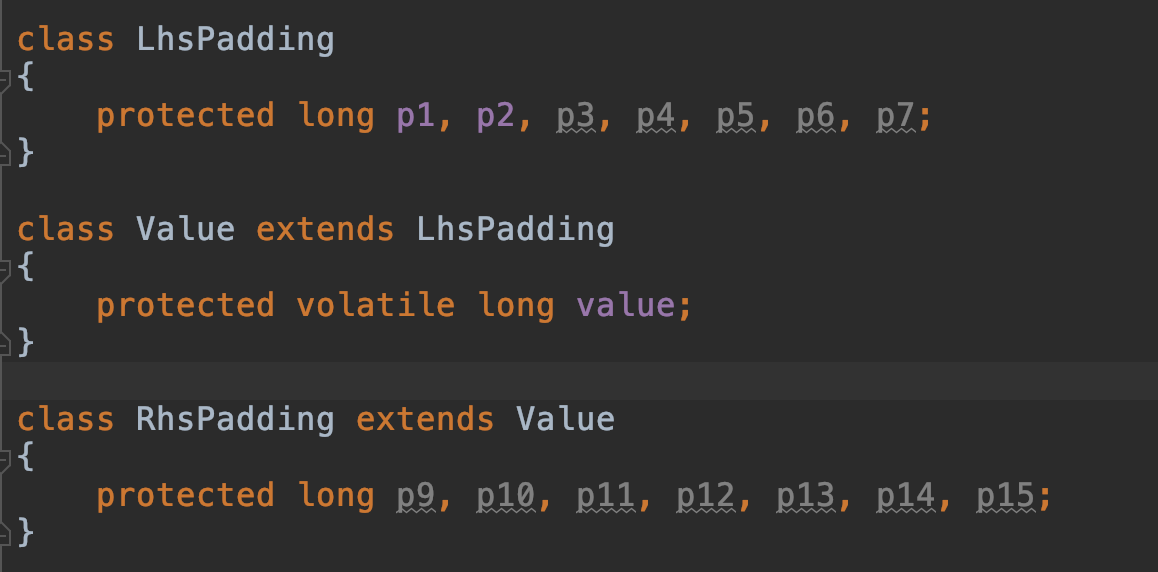
这段代码来自Disruptor,Disruptor是一个基于内存的高性能异步处理框架。这段代码是啥子意思呢?
这还要从CPU缓存讲起。
假设CPU有三级缓存L1、L2、L3,并且CPU有2个核心,那么,两个核心中都有各自的L1、L2,也就是说不同核心使用的是不同的L1、L2缓存,既然使用了不同的缓存,那肯定就涉及到了数据一致性的问题,这里暂不探讨CPU的数据一致性协议(MESI协议),但一致性协议会带来性能问题,之后会简单介绍一下:伪共享问题。
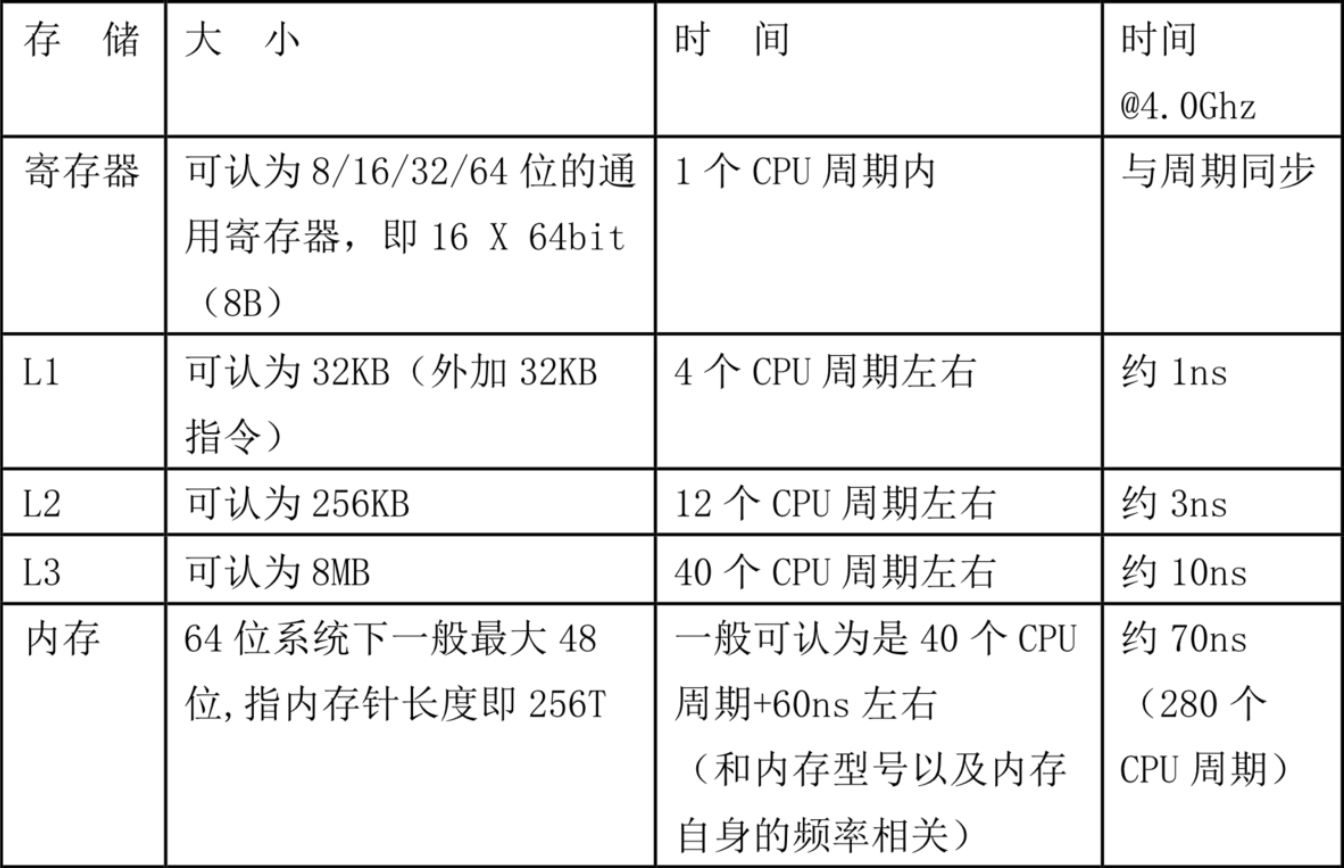
不同Cache的速度不一样,L1>L2>L3>内存,他们的速度比如下:
当L1miss了之后,会访问L2,如果L2命中,会将L2要访问的数据,以及该数据之后的一部分数据一起加载到L1中来,因为根据程序的局部性原理,该数据周围的数据大概率会在接下来的程序中被访问。
那么一次究竟加载了多大的数据到内存中呢?
64B,每次从更慢的缓存中都会以64B大小的数据块为单位加载到更快的缓存中。
伪共享问题
所谓的伪共享问题,是由于CPU的一致性协议引起的。由于每个CPU核心拥有自己的L1、L2缓存,但是由于数据是以64B为单位从低级缓存中加载过来的,所以,这64B的数据可能同时包含两个不同核心需要访问的数据,那么,当一个CPU核心修改了其中的某些数据,而另一个CPU核心是从自己的缓存中读取数据,那就会出现数据不一致问题。为了让数据保持一致,如果一个CPU核心修改了被共享到不同缓存中的数据,那么所有拥有这块64B数据的缓存就会被通知无效,在下次访问这块数据时,CPU发现这是一块无效数据,就会直接从内存中读取。
由上面的表可以看出,内存的访问速度比L1慢两个数量级,比L3也要慢一个数量级,如果在高并发场景下频繁发生伪共享问题,导致CPU频繁直接从内存中拿取数据的话,就会导致系统性能下降。
有什么好的解决办法没有呢?有,请看文章开头的代码。
1 | class LhsPadding |
这段代码保存了一个long数据并为了避免伪共享做了一件暴力的事情,那就是加入Padding数据,前后各加入了7个long,加上自己前后刚好就是64B的大小,这样就能保证这个long值不与其他的值共享缓存,这样就避免了伪共享问题。但是,避免伪共享并不代表着cache可以100%命中这个数值而不用去访问内存,因为在这个字段自己被并发访问时,仍需要与内存进行数据同步,保证该字段的可见性(该代码中就加入了volatile字段保证了可见性)。
不要混淆伪共享和可见性,伪共享是不同核心访问同一个Cache块中的其他数据引起的缓存失效,而可见性是为了保证不同线程对于同一数据的范围具有数据一致性。说白了,伪共享问题是和自己同一数据块的其他数据被修改引起的,自己是被牵连的,而可见性问题是自己本身被修改了,需要告诉其他可以访问自己的线程,本质上是两个完全不同的问题,只不过现象都是缓存失效。这段代码只是针对解决伪共享问题,对于可见性还是只能老老实实的加上了volatile字段。
番外1,演示一下CPU缓存命中与不命中的性能差异
1 | public static int length = 32 * 1024 * 1024; |
运行结果:

上图中用了6个long去填充一个缓存块(为啥是6个呢?因为还有对象头呀,不过这里代码写错了一点,数组对象头有24B,所以应该只有5个long就可以去填充一个缓存块了,但是没有太大关系,还是可以看出明显的效果)。
是不是很神奇,同一个数组不同的访问顺序,性能上有4倍的差别。
番外2,MESI协议
每个64B的缓存块都有一个2bit标志位,用于标识四种状态:
- modify:当前CPU cache拥有最新数据(最新的cache line),其他CPU拥有失效数据(cache line的状态是invalid),虽然当前CPU中的数据和主存是不一致的,但是以当前CPU的数据为准;
- exclusive:只有当前CPU中有数据,其他CPU中没有改数据,当前CPU的数据和主存中的数据是一致的;
- shared:当前CPU和其他CPU中都有共同数据,并且和主存中的数据一致;
- invalid:当前CPU中的数据失效,数据应该从主存中获取,其他CPU中可能有数据也可能无数据,当前CPU中的数据和主存被认为是不一致的;
对于invalid而言,在MESI协议中采取的是写失效(write invalidate)。
后面具体的情况就不一一分析了,我自己也没有仔细看完(逃
总结:
今天简单的讲了一下CPU的缓存,告诉大家:Java也是可以做CPU优化的!虽然这种优化只在非常极端的情况下会被用到,但是在今天架构满天飞,中间件崛起的大环境下,Java跟高性能这个话题的关系越来越密切,市面上出现了很多Java的高性能框架,例如netty,netty中也用到了今天讲的优化方法:
1 | // InternalThreadLocalMap |
这是netty中的一段代码,是不是会心一笑。
如今大量的开源框架都使用netty作为传输层框架,例如hadoop,dubbo等等,netty的性能和可用性都到达了一个巅峰,netty的作者也曾说过:“netty的每一个细节都经过了精心的设计”。
我想说的是,也许作为一名Web工程师,这些优化方法离你非常的远,可能几乎不会用到,你的目光可能更多的集中在SQL的优化或者业务代码上,但是,如果想更近一步做一个架构师,或者中间件专家等等,都需要掌握计算机系统底层原理甚至是硬件原理,以及掌握自己使用的语言是如何与系统相互作用的,并逐渐精通。我自己也在往这方面努力,希望能和大家共同进步。
下一节会介绍一下Java对于磁盘的操作~
哦对了,你知道为什么说二分法的性能不好了吗?

